 backup
backup
Diferentemente da crença popular que “tudo o que está on-line permanece disponível”, a Internet não guarda tudo. Em uma postagem anterior desta série, analisamos nove cenários em que podemos perder o acesso ao conteúdo on-line. Fornecemos ainda um guia detalhado sobre quais informações são essenciais para realizar o processo de backup de forma rápida em seu computador. Hoje, abordaremos como salvar facilmente páginas da Web no seu computador, organizar esses arquivos e lidar com situações em que um site favorito desaparece.
Suponha que você queira salvar uma postagem de blog com uma receita, compilar uma bibliografia para um artigo de pesquisa ou preservar uma publicação on-line por motivos legais. Todos os itens acima são publicados como páginas da Web, que tendem a desaparecer no momento errado. Quer relembrar notícias da música e fofocas de 2005? É uma pena, mas o site MTV News fechou e todos os seus artigos e entrevistas não estão mais disponíveis. Quer verificar links da Wikipédia? 11% deles não funcionam mais, embora estivessem funcionando no momento da publicação do artigo. Esse fenômeno de “quebra de links”, a exclusão gradual ou realocação de conteúdo online, está se tornando um problema crescente. Cerca de 38% das páginas que existiam há dez anos não estão mais acessíveis hoje. Portanto, se houver uma página da Web que você goste ou precise, a opção mais sábia é criar um backup.
Como salvar uma página da Web no computador
Como uma página da Web é composta por dezenas ou até centenas de arquivos, o backup demanda um certo esforço. Veja as principais formas de fazer isso:
Salvar somente texto como um arquivo HTML. Selecione o comando ou botão do menu “Salvar página como…” no navegador e, em seguida, selecione “Página da Web, somente HTML”. Isso salva apenas o texto da página da Web, sem imagens ou outros elementos visuais.
Salvar texto e imagens. A opção “Página da Web, completa” cria, além de um arquivo HTML, uma pasta com o mesmo nome contendo todos os elementos gráficos, estilos e scripts da página. Uma desvantagem dessa opção é que salvar muitos arquivos auxiliares pode sobrecarregar sua unidade. A opção “Página da Web, arquivo único” é mais conveniente, agrupando a página da Web e todos os seus recursos em um único arquivo .mhtml. Esse formato abre facilmente no Chrome e no Edge, mas pode apresentar problemas em outros navegadores. Esse formato não está disponível em todos os navegadores, mas ao instalar a extensão SingleFile (disponível para a maioria deles), é possível salvar a página da Web completa, incluindo seu conteúdo de mídia, como um único arquivo HTML que abre perfeitamente em todos os navegadores modernos.
Imprimir em PDF. Para preservar o conteúdo principal da página, mas descartar menus e banners, sua melhor opção é Imprimir em PDF. O arquivo resultante pode ser aberto em qualquer computador.
Com qualquer uma dessas opções, verifique se o texto principal que você deseja manter permanece legível ao abrir o documento.
Uma maneira mais fácil de salvar uma página da Web
Os métodos descritos acima são um pouco demorados e sobrecarregam seu disco rígido. Para maior conveniência, use um serviço dedicado, como o Pocket (anteriormente Read It Later), wallabag ou Raindrop.io. Todos funcionam da mesma maneira: você envia um link, e o serviço recupera o documento, remove quaisquer elementos desnecessários e o salva com todas as ilustrações no seu armazenamento pessoal online. Mesmo que a página original seja excluída ou modificada, a versão desejada permanece em seu arquivo. Esses serviços permitem agrupar e classificar seus links, pesquisar textos e exibir as páginas salvas em qualquer dispositivo. Para desktop, há uma extensão disponível para todos os principais navegadores; e para dispositivos móveis, há um aplicativo.
Todos esses serviços oferecem um arquivo “eterno” apenas com uma assinatura premium, ou seja, é necessário pagar pela conveniência. Dito isso, o Wallabag é de código aberto, então é possível instalá-lo em seu próprio servidor, evitando ter que pagar por serviços de terceiros e o risco do serviço ser encerrado.
Alguns aplicativos de anotações também podem salvar páginas da Web completas. Isso inclui o Evernote, em que o recurso é chamado de “Web Clipper”.
Como salvar uma página da Web para outras pessoas
Se precisar de uma cópia não apenas para si, mas para compartilhar uma determinada versão da página com outras pessoas, é necessário um serviço de arquivamento público.
O mais conhecido é o Internet Archive (archive.org) e seu Wayback Machine. Outras opções incluem archive.today (também conhecido como archive.is), perma.cc e megalodon.jp. Essas opções funcionam de forma semelhante: sob demanda do usuário ou automaticamente. Elas visitam as páginas da Web e salvam as cópias em um servidor.
Para solicitar o arquivamento de uma página da Web, acesse web.archive.org e insira o endereço completo na caixa Save Page Now. Depois de clicar em Save, uma janela aparece, descrevendo todos os componentes carregados da página, além de um link permanente para o site em seu estado preservado. Fica assim: https://web.archive.org/web/20240918234814/https://www.kaspersky.com/blog. O link exibe o endereço da página e a hora exata em que ela foi salva. Isso é perfeito para fins de arquivamento.
O registro no archive.org permite gerenciar uma coleção desses links, fazer capturas de tela de sites salvos e baixar cópias deles no formato especial de arquivamento da Web WACZ.
No archive.org, você pode visualizar versões antigas de sites e salvar o estado atual de qualquer página, como nosso blog, por exemplo
Ao abrir o link do arquivo, a página salva aparece com um carimbo de data/hora indicando quando o instantâneo foi tirado. Esse recurso é útil para rastrear e demonstrar alterações nos dados do site: flutuações de preço, atualizações da descrição do produto, notícias editadas e informações excluídas. O último é especialmente importante para pesquisadores de história e cultura que dependem de sites desativados. Abaixo, podemos ver uma das primeiras versões do GeoCities, um serviço de hospedagem na Web que foi popular no passado e permitia criar “páginas iniciais”, se expressar e encontrar amigos com interesses semelhantes, muito antes das redes sociais. É somente graças ao Wayback Machine que podemos vê-lo agora, pois o site deixou de existir em 2016.
Um presente para os veteranos: uma das primeiras versões do GeoCities.com
Como encontrar conteúdo da Internet excluído ou uma versão antiga de um site
Para visualizar uma versão antiga de qualquer site:
- Abra archive.org.
- Insira o endereço completo do site ou de uma página específica na caixa ao lado do logotipo e clique em Enter. Se a URL exato for desconhecida, você pode inserir o nome do site ou palavras que a descrevam bem.
- Selecione o site desejado na lista. Os resultados mostram rapidamente quantas cópias estão arquivadas e para qual período.
- Use o calendário para selecionar quais das cópias salvas do site deseja visualizar. As datas para as quais há uma cópia salva estão circuladas, quanto maior o círculo, mais cópias foram feitas naquele dia.
- Selecione a data desejada para ver o site salvo. Observe que carregar uma cópia do arquivo pode levar alguns minutos.
- O gráfico de calendário acima da cópia do site permite que você navegue para versões mais antigas ou mais novas.
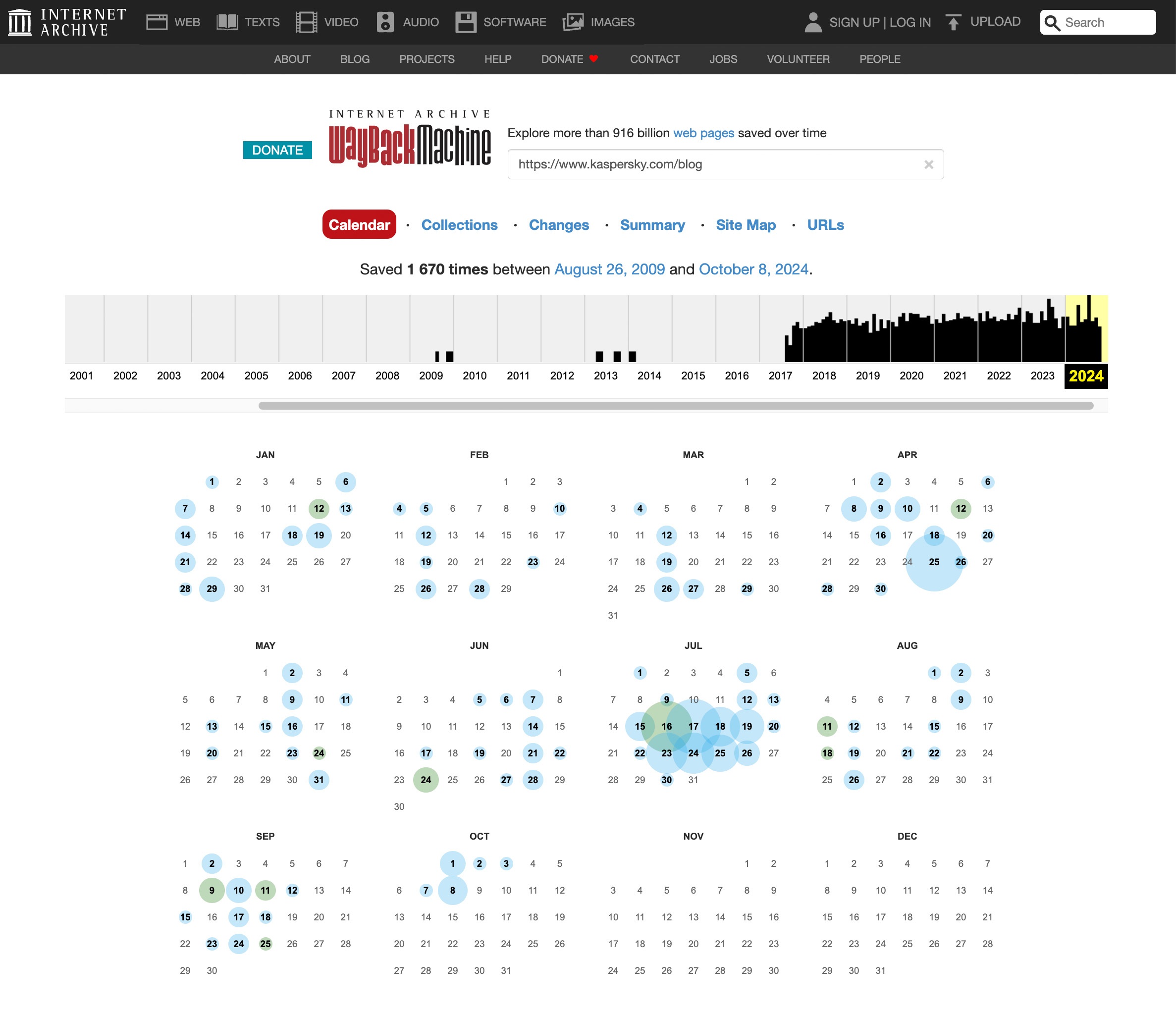
Como explorar versões antigas de sites em web.archive.org
Você pode copiar o link da barra de endereços para acessar o site arquivado diretamente, sem passar pela interface de pesquisa.
E se o archive.org não puder ajudar
A fundação por trás do archive.org às vezes atende às solicitações de detentores de direitos autorais e outras partes autorizadas para excluir determinados sites do Wayback Machine. Além disso, o serviço nunca teve como objetivo preservar toda a Internet, então a página que você precisa pode nunca ter sido indexada. Nesses casos, tente procurá-la em outras cápsulas do tempo.
O Archive.today (também conhecido como archive.is) não salva páginas automaticamente, somente a pedido dos usuários. Isso, entre outras coisas, elimina a necessidade de seguir as instruções para robôs de pesquisa (robots.txt) e garante que o arquivo contenha documentos não disponíveis na Wayback Machine.
Outro projeto importante de arquivamento da Web é o perma.cc, criado por um consórcio das principais bibliotecas do mundo. No entanto, ele é gratuito apenas para as organizações participantes. Os usuários individuais podem assinar um plano pago, com preços baseados no número de links arquivados.
Uma alternativa poderosa aos arquivos especializados é o conteúdo em cache dos mecanismos de pesquisa. Para indexar páginas, os mecanismos de pesquisa recuperam seu texto, disponibilizando uma versão bruta, mas legível de quase todas as páginas. Por muito tempo, o cache do Google foi o mais acessível, mas no início de 2024, o gigante das buscas removeu o link direto para seu cache dos resultados da pesquisa. O serviço ainda funciona, mas acessá-lo diretamente é muito difícil.
Portanto, é melhor usar extensões de navegador que facilitem o trabalho com os arquivos da Internet. Por exemplo, se um link levar a uma página excluída ou a um site extinto, a extensão Web Archives redireciona o usuário diretamente a uma cópia arquivada em web.archive.org, archive.today ou perma.cc, ou exibe uma versão em cache do Google, Bing ou Yandex.
Como salvar dados de outros serviços on-line
Além das páginas da Web, há muitos outros serviços on-line, de álbuns de fotos e notas a redes sociais, com dados que também desejamos salvar. Embora as recomendações variem conforme o tipo de dado e serviço, agrupamos todas as instruções relacionadas sob a tag “backup” para sua conveniência. É possível ler sobre como criar backups para:
E não se esqueça de proteger seus backups contra ransomware e spyware!
 Dicas
Dicas